GRCon 2021 - Capture The Signal
I participated in the GRCon CTS (Capture The Signal) challenge (pseudonym: e), which took place from 20th to 23rd, September, 2021.
I solved all challenges but one and ended up first, here are my writeups for the different tasks.
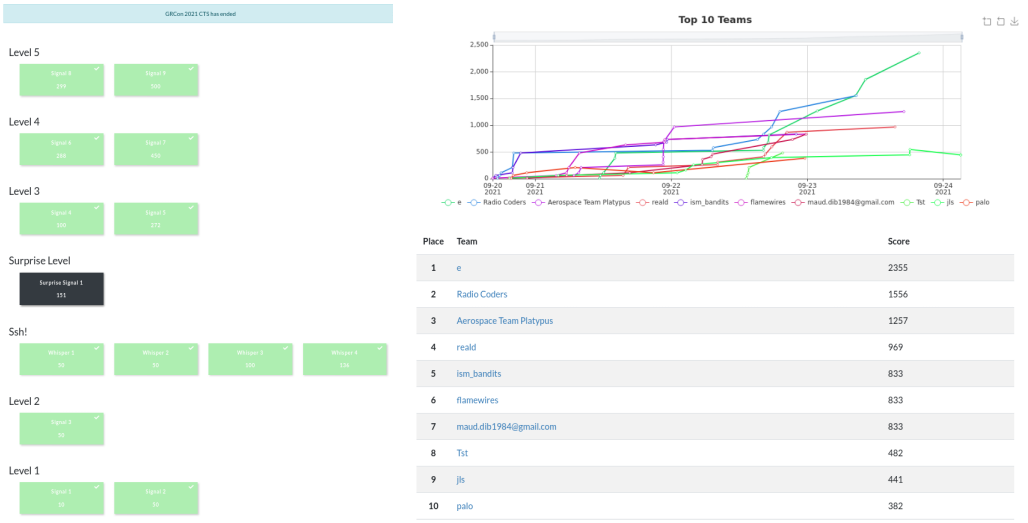
Challenges solved and top 10
First, I’d like to thank the challenge creators and organizers of the event for their amazing job. I had a lot of fun working on the last signals.
Context
Part of those challenges were published for a previous Capture The Signal event, at HW.IO 2021 last summer. I had participated in this one too, which helped me solve 2 challenges (one which I had solved at HW.IO, another which was not solved but where some public information already existed).
The flags came in two format, unless specified :
- TMCTF{…}
- FLAG:
Typically, I use a mix of GNURadio / Python to solve signal challenges. Sometimes more specific tools like Inspectrum/Universal Radio Hacker
Tip: The first thing I do for every CTF signal is to display the waterfall (Inspectrum’s one is nice) and show simple demodulations with Python :
import numpy as np
from matplotlib import pyplot as plt
sig = np.fromfile("/path/to/file", dtype=np.complex64)
a = np.abs(sig) # Amplitude
p = np.angle(sig) # Phase of the signal
f = np.diff(np.unwrap(p)) # Frequency of the signal
ax = plt.subplot(311)
plt.title("Amplitude")
plt.plot(a)
plt.subplot(312, sharex=ax)
plt.title("Phase")
plt.plot(p)
plt.subplot(313, sharex=ax)
plt.title("Frequency")
plt.plot(p)
plt.show()Challenges
Level 1
Signal 1
File: signal1.iqdata
This is a simple spectrum painting challenge, we just need to display a waterfall of the signal with a sufficient resolution. Typically, GNURadio doesn’t display the flag properly using default parameter, one needs to improve the “Refresh Rate” to see the flag.
Inspectrum has a nice waterfall, although the dezoom is limited.

Waterfall of Signal 1 on Inspectrum
We can read the flag off it (although frequencies are reversed) : “FLAG:GRCon2021 CTS This is Level0”
Signal 2
File: signal2.iqdata
The description of the challenge is “Listen carefully.”. We can import the signal in Audacity (File -> Import -> Raw Data ; two channels, 48kHz (guess), 32-bits little endian floats), but when playing we hear a constant tone hiding the voice.
With Inspectrum, we see that there is indeed a strong CW at 1kHZ, that we need to remove. The block “DC blocker” in GNURadio can do just that.
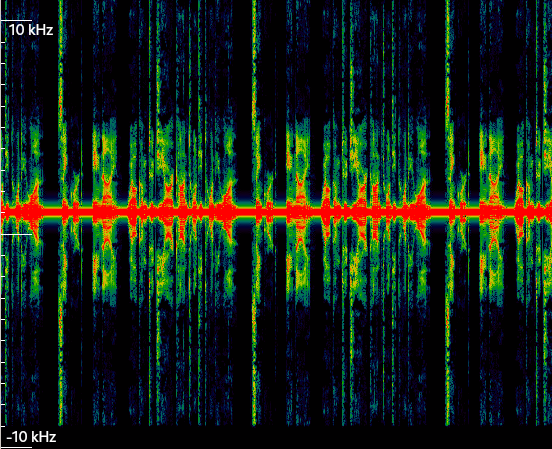
Waterfall of Signal 2 on Inspectrum
The flowgraph below does just that : - Mix the signal with -1kHz -> Tone gets centered - DC blocker -> Tone is removed - Mix the signal with 1kHz -> Undo previous mixing
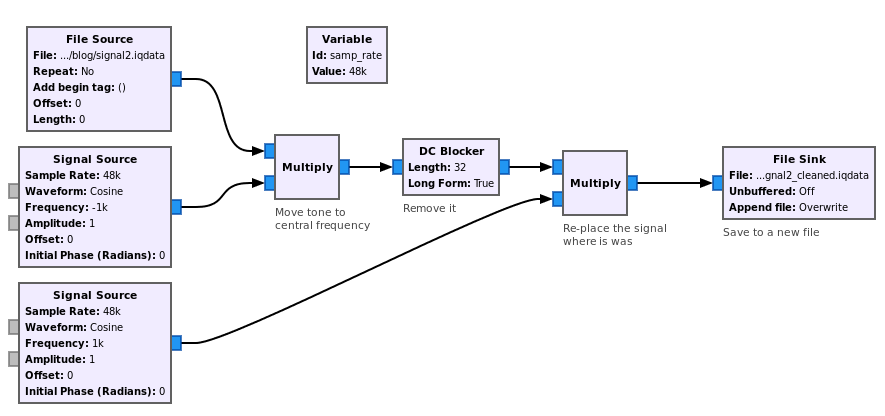
Remove tone of Signal 2 on Inspectrum
Now, using Audacity we can understand the voice, which repeats the flag “Welcome to GRCon2021 Sync Word: A9”
An easier way to solve this was to feed the signal directly to GQRX, which does a proper AM demod (and outputs a cleaner sound).
Level 2
Signal 3
File: signal3.iqdata
No real indication for this one, except it’s “different”.

Waterfall of Signal 3 on Inspectrum
From the waterfall we can infer the following : - There is a single carrier which is turned on and off. - The duration of the on or off moments varies, but seems to be multiple of the same unit.
This is indicative of an On-Off Keying (OOK) modulation, which can further be confirmed doing an AM demodulation of the signal :
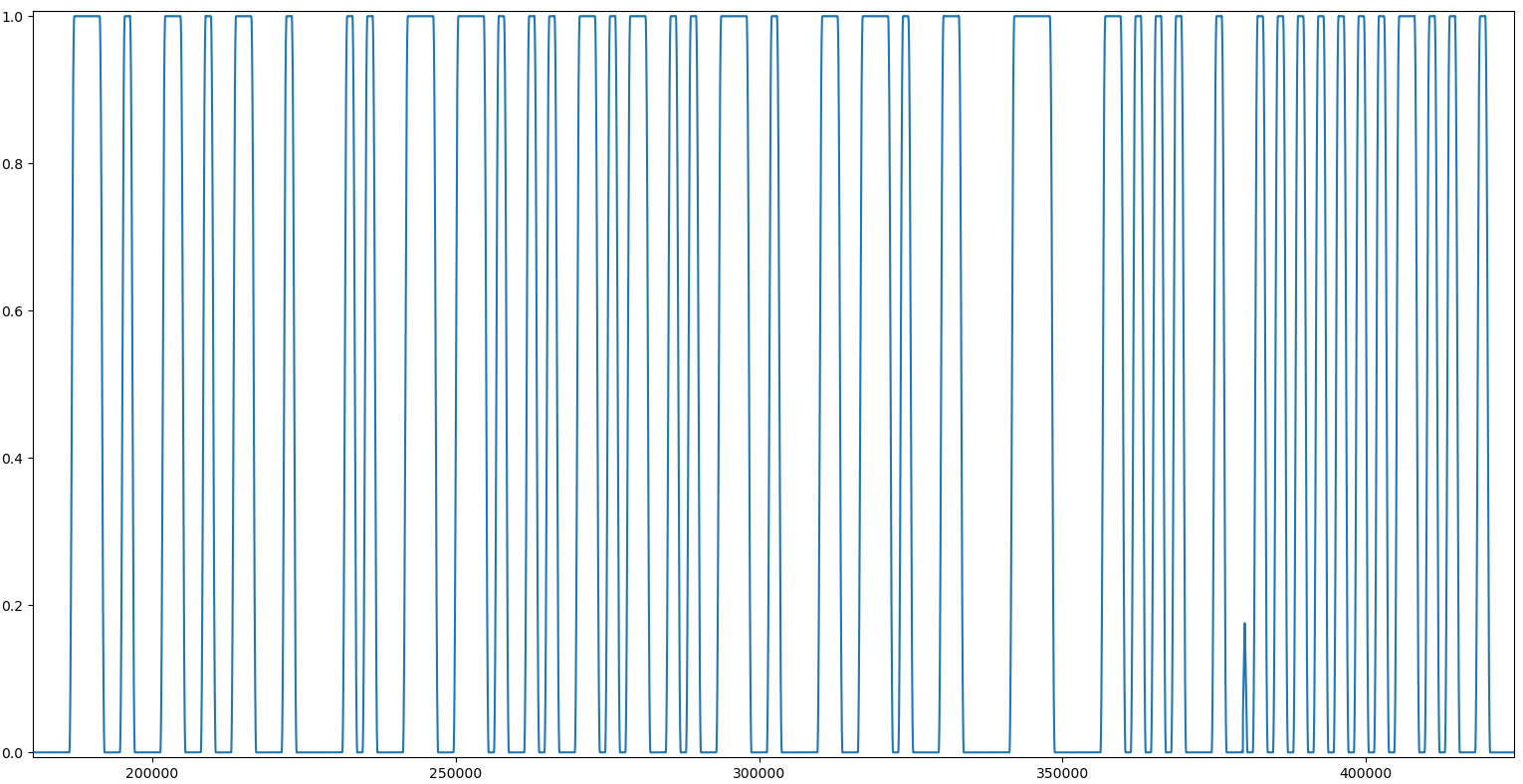
AM demod of Signal 3 using numpy/matplotlib
To demodulate that, we need to recover the number of samples per symbol.
In order to do that, we can count the number of samples which compose a symbol (high / low value) and make a histogram of it. We should see several peaks, evenly spaced.
import numpy as np
from matplotlib import pyplot as plt
sig = np.fromfile("signal3.iqdata", dtype=np.complex64)
ampl = np.abs(sig) # AM demod
# Count number of samples per symbol
thresh = 0.5 # Anything above is a 1, else a 0
count = []
c = 1
prev = 1 if ampl[0] > thresh else 0
for i in ampl[1:]:
if i > thresh:
if prev == 1:
c += 1
else:
count.append(c)
c = 1
prev = 1
else:
if prev == 0:
c += 1
else:
count.append(c)
c = 1
prev = 0
plt.hist(count, bins=50)
plt.show()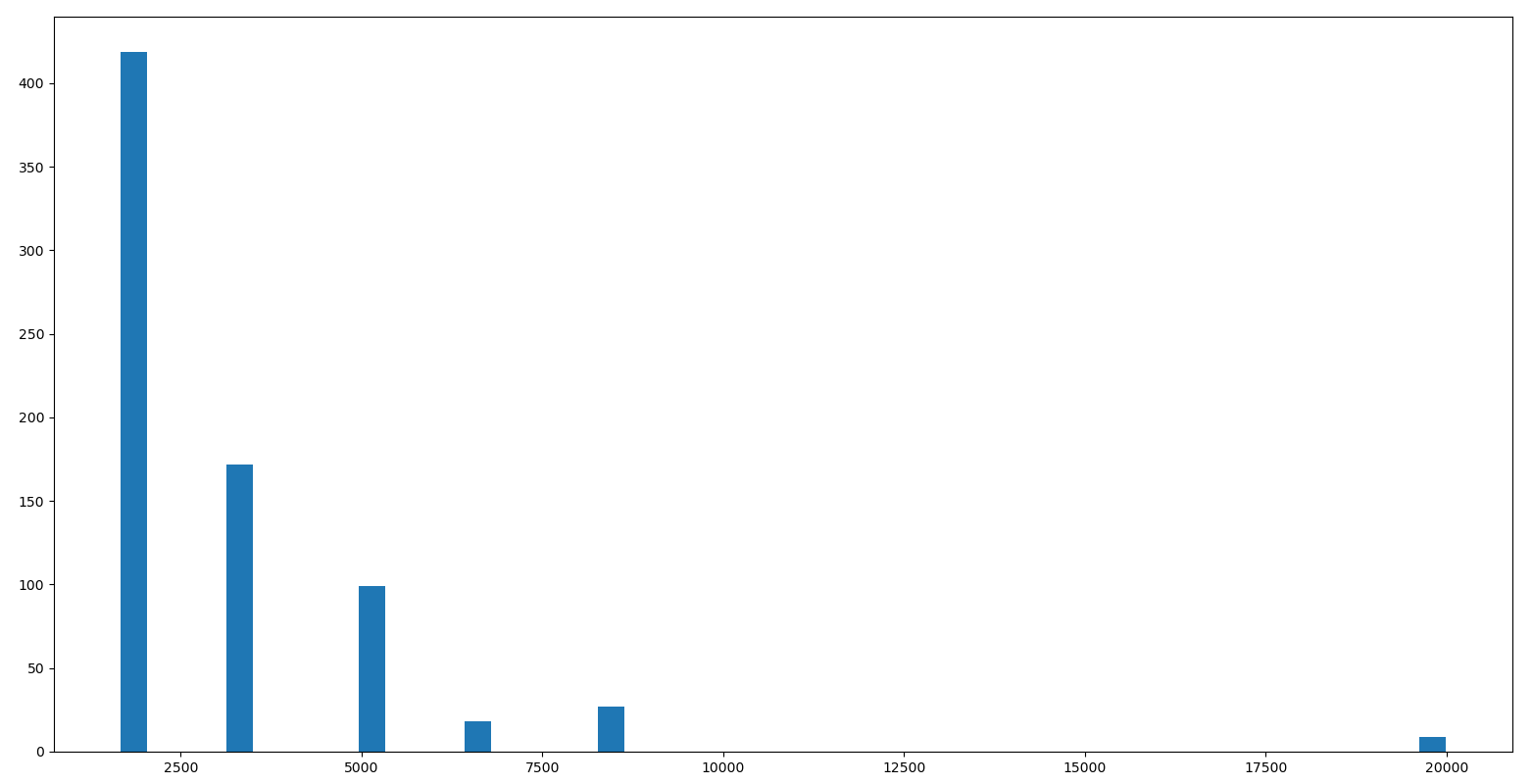
Retrieve samples per symbol for signal 3
The result is exactly as expected, the larger spaces may be some sort of packet separation. We can conclude that there are about 1666 samples per symbol.
A quick way to decode the data is to reuse the “count” array from the Python script and for each value, add the current symbol’s value count // sps times:
if the amplitude is high for 3334 samples, add “11”, if it is low for 5000 samples, add “000”, …
res = ""
sps = 1660 # Take a bit lower to avoid rounding problems
curr_bit = "1" if ampl[0] > 0.5 else "0"
for c in count:
res += curr_bit * (c // sps)
curr_bit = "0" if curr_bit == "1" else "1"
# Just try all possible paddings so we can read the flag
for i in range(8):
s = hex(int(res+i*"0",2))[2:]
if len(s) % 2: s = "0" + s
print(bytes.fromhex(s))We have the proper solution among the results: b'\nSYNC:0x5DUU\xa9\x00\x0eFLAG:SYNC:0x5DUU\xa9\x00\x0eFLAG:SYNC:0x5D...'
The flag is “FLAG:SYNC:0x5D”. We also retrieve the sync word from signal 2.
Note: “UU” is 0x55555 or 0b0101010101010101; it is standard to start a transmission with such a pattern (0xAA also works).
Ssh / Whisper
Those challenges were different. The goal was to process ham radio contacts and make some statistics of them.
We have a unique file, reused for all challenges : wsprspots.csv. For each challenge, we have a question to answer about this database of contacts.
The first three lines of the file are:
Reporter,Distance,Call Sign,Reporter's Grid,Grid
KA7OEI-1,2955,1Z2CPJ,DN31uo,FN25dj
DB9OH,816,2E0SXX,JO52ji,IO91
The “Reporter” is the station (~Call Sign) of the listener who reports a contact, distance is the distance of the contact, Call Sign is the identifier of the emitter, and the grids are the locations of the emitter/listener.
In order to correctly treat the file, I removed the header line (else it’s interpreted as a contact in my solutions). For each challenge of this track, we had to answer a question.
Whisper 1
Question: In the attached file, what country is the reporter with the most reports located in?
We can do that with standard Unix tools:
cat wsprspots.csv | awk -F"," '{print $1}' | sort | uniq -c | sort -n
The reporter with most contacts is OE9GHV (13916 contacts). Its station is located in JN47wk, which is in Austria. The flag is “Austria”.
Whisper 2
Question: For the reporter you identified in Whisper 1, what was the country of origin of the most distant received message?
Again, Unix tools are sufficient:
grep "^OE9GHV" wsprspots.csv | awk -F"," '{print $2}' | sort -n
We can see the longest contact was made at a distance of 18173km, with a station located at RF74ci. The flag is New Zealand.
Whisper 3
Question: what percent of the other nodes are unreachable regardless of hop count from “F5MAF”? Assume any node that is visible to a reporter may be reached by the reporter. Round to two decimal places.
This one had a try limit of 25.
This is a typical graph question, we need to build a graph out of contacts and traverse it from the node F5MAF.
class Graph(object):
def __init__(self, fname):
self.edges = {}
lines = open(fname, "r").readlines()
for line in lines:
src, _, dst, _, _ = line.split(",")
self.add_vertex(src,dst)
def add_vertex(self, v, w):
if v not in self.edges:
self.edges[v] = set()
self.edges[v].add(w)
if w not in self.edges:
self.edges[w] = set()
self.edges[w].add(v)
def reachable_from(self, node):
visited ={k: False for k in self.edges.keys()}
# Standard Depth-First-Search
visited[node] = True
lst = [node]
while len(lst) > 0:
v = lst.pop()
for w in self.edges[v]:
if not visited[w]:
visited[w] = True
lst.append(w)
return visited
g = Graph("wsprspots.csv")
visited = g.reachable_from("F5MAF")
t_t, t_f = 0,0
for _,v in visited.items():
if v:
t_t += 1
else:
t_f += 1
print("{:.2f}".format(t_f/(t_f+t_t-1)*100))
# 2.12We need to subtract 1 from the total at the end because the question asks for the number of unreachable nodes from the other nodes, meaning without including F5MAF. The flag is 2.12.
Whisper 4
Question: for each reachable destination node from “IZ7BOJ”, determine the minimal number of nodes necessary to form the path. What is the average of these minimal-path node counts required across the different reachable destinations? Assume any node that is visible to a reporter may be reached by the reporter. Include source and destination nodes in the each minimal-path node count. Round to 2 decimal places.
This one is another graph question. Because all hops have the same distance, we can compute the shortest paths using the breadth-first-search algorithm. We can simply adapt the program from Whisper 3.
class Graph(object):
# ...
def distance_to(self, node):
distances = {k: -1 for k in self.edges.keys()}
# Standard Breadth-First-Search
distances[node] = 0
to_visit = [(node, 1)]
while len(to_visit) > 0:
v,d = to_visit.pop()
for w in self.edges[v]:
if distances[w] == -1:
distances[w] = d+1
# This is the trick to BFS: process nodes in the order
# they are enqueued in the list. This guarantees all nodes
# with distance 1 are traversed, then all nodes with
# distance 2, etc...
to_visit.insert(0, (w, d+1))
return distances
distances = g.distance_to("IZ7BOJ")
nb, total = 0, 0
for _, d in distances.items():
if d > 0:
nb += 1
total += d
print("{:.2f}".format(total/nb))
# 3.33The flag is 3.33.
Level 3
Signal 4
File: signal4.iqdata
We do not have any indication on the description of the task.

Waterfall of signal 4
On the waterfall, we see several bursts, occupying the same band. When zooming on a burst, we see several frequencies, which may indicate a FSK-type modulation.
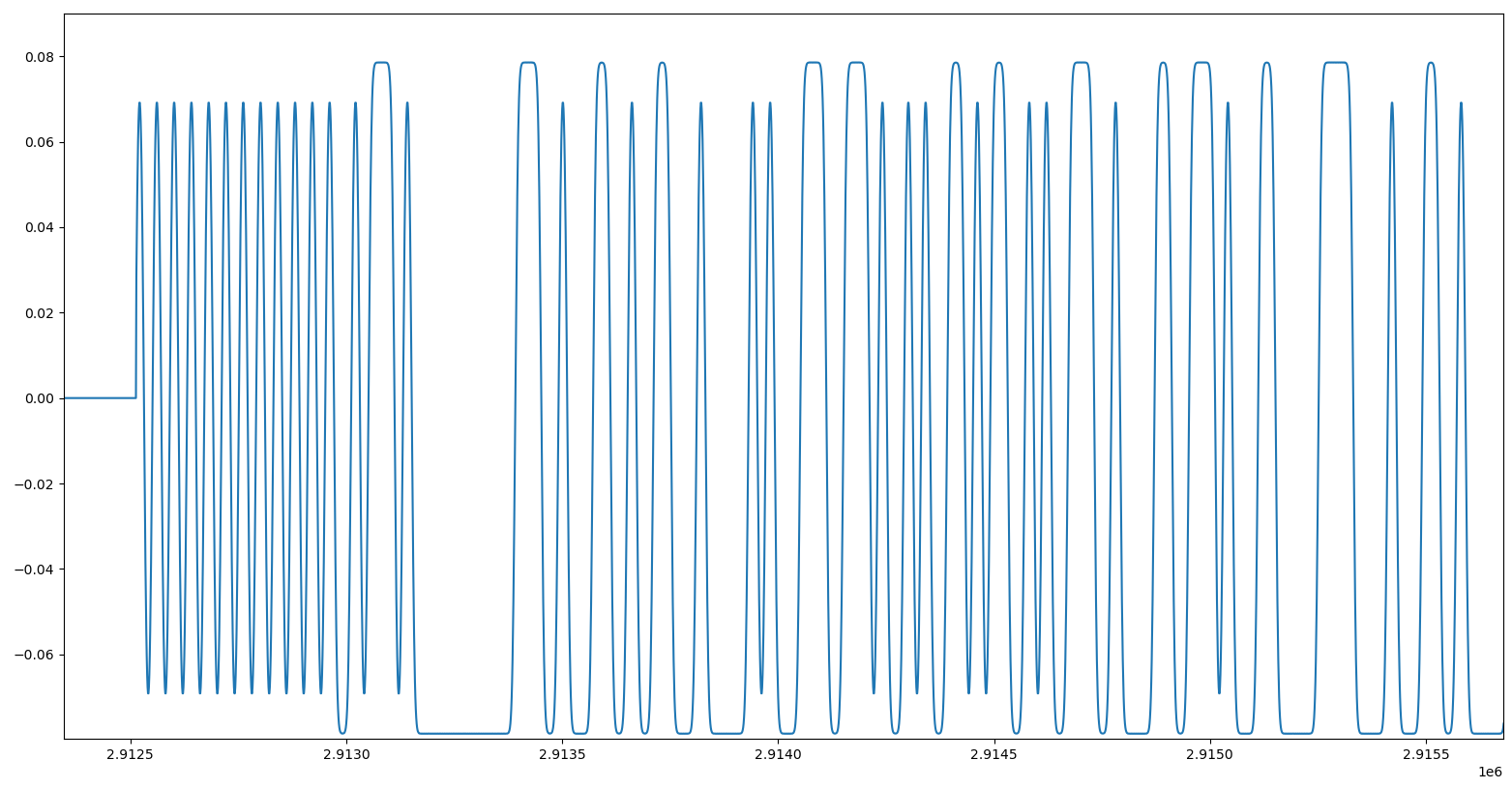
Instantaneous frequency of a burst in signal 4
When plotting the instantaneous frequency of a burst, we clearly see two possible values for the frequency: above 0 or below 0 which indicates a 2-FSK modulation. We could decode it by hand, but in that case URH does everything automatically. Just open the file in URH, 2-FSK is recognized and bursts are put in several packets already.
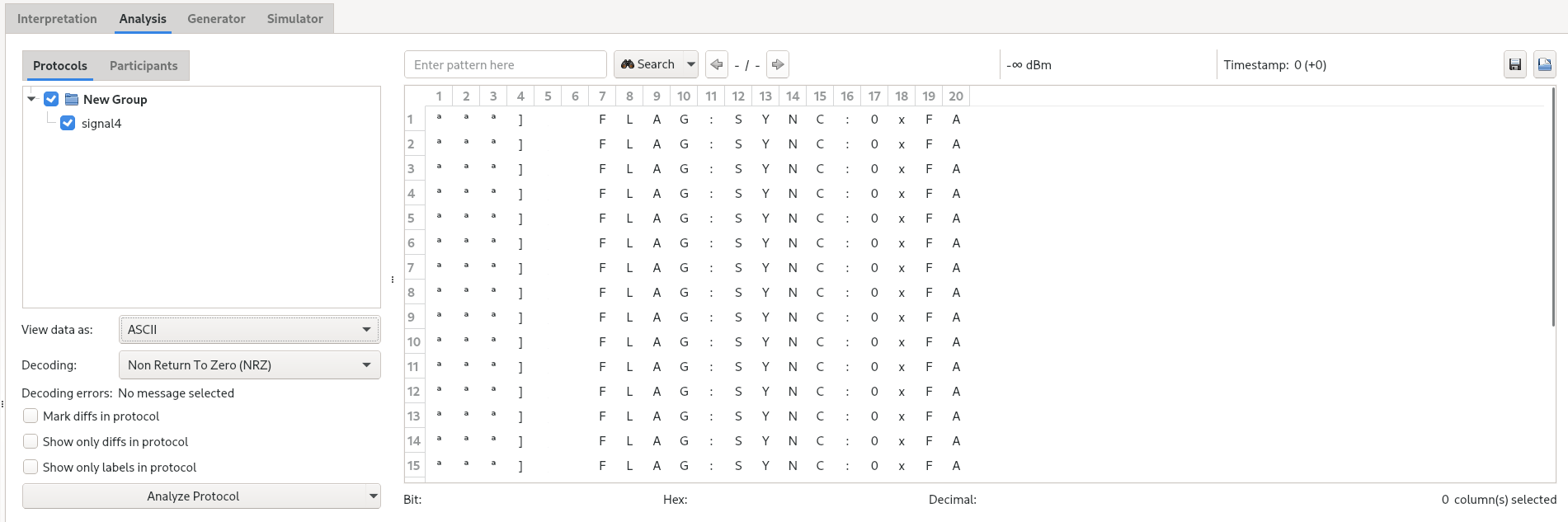
Signal 4 analysis with Universal Radio Hacker
In the “Analysis” tab, we can view the decoded packets as ASCII, which gives the flag : “FLAG:SYNC:0xFA”.
Signal 5
File: track.wav
I had solved this one at HW.IO 2021 CTS. I re-did all the steps to be sure the flag did not change, but already knew of the correct path.
The description is :
Welcome back to the 80s!
In the 80s there was no such things like Signal or Telegram. We had different, ancient
means to communicate. Sometimes even the physical layer of the communication
stack was...unusual!
But you may not care, because you came for the flags! Come for the flags, stay for the hack!
Right?
You see, we wish we could just plant a simple flag, but we thought...what a boooring idea!
So we decided to go a bit different for this challenge.
Instead of hiding the complete flag as is, we splitted it into many parts. Once you find
all the parts, you must concatenate them sequentially using an underscore character "_" as
a separator.
The final flag will look like this:
TMCTF{part1_part2_..._partN}
Feel free to keep TMCTF{ and the trailing } out of the flag: the system will accept a flag
with or without those.
We don't remember how many parts we hid in the challenge, sorry, so we can't really help:
you just follow the leads and you'll find them all! :-)
The track we have is an audio clip, we understand that there are several parts hidden inside it. When listening to it with Audacity, we can clearly identify at least 2 parts : a Morse message and something that is transmitted in audio tones. There are other sounds around the end which may be yet another part of the flag.
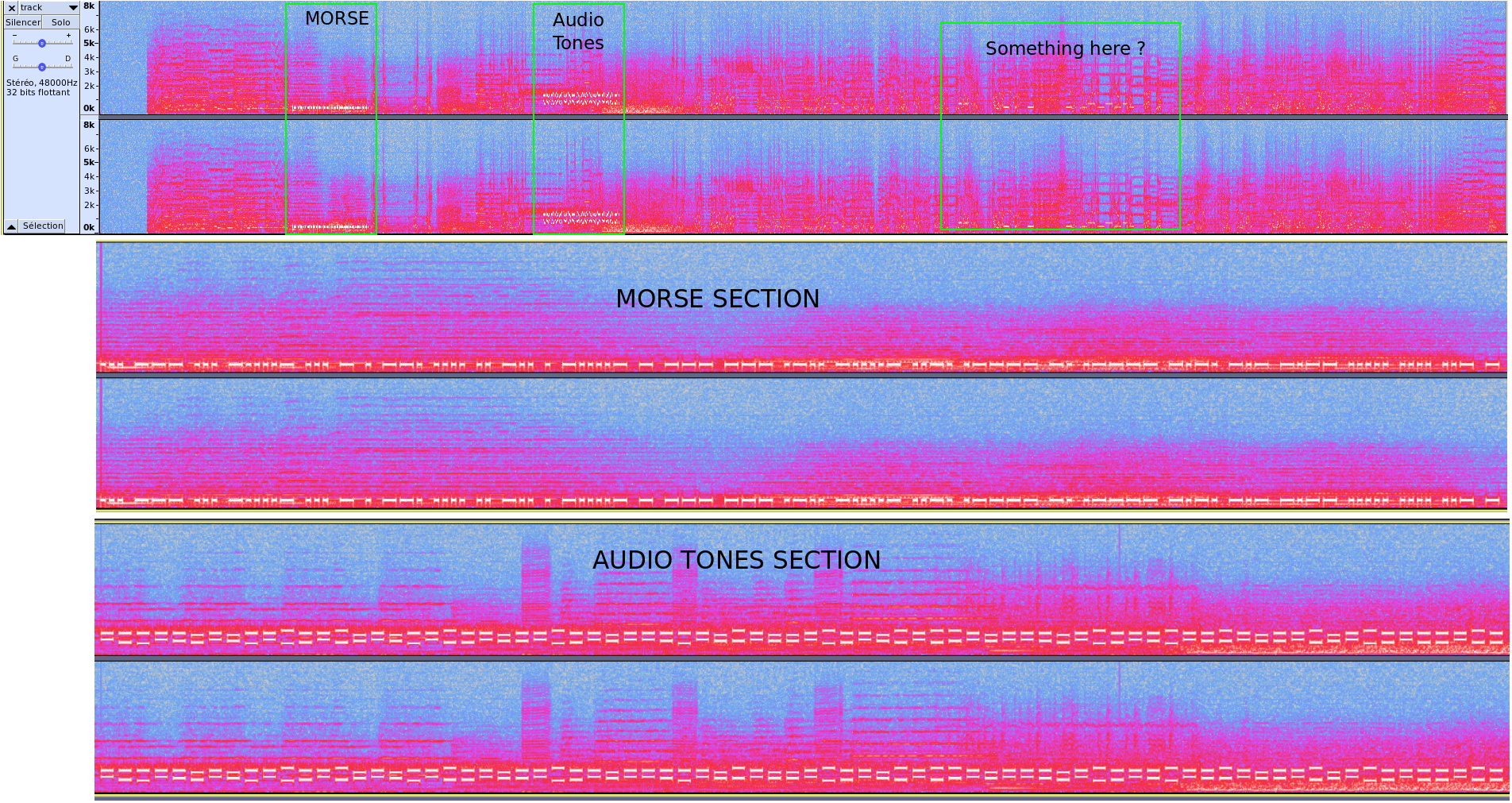
Sections in audio track
Part 1
The Morse section was decoded by hand. It translates to “SOS-STEGHIDE-TOOL-F1N1CKY5HUT”. Steghide is a software to hide files in other files using steganography. It can take a password as input.
We can extract the data from the track using the command line steghide extract -sf track.wav -p F1N1CKY5HUT; it says that a file “iq-data.cfile” was indeed hidden inside the track and successfully extracts it.
Part 2
We just gained an IQ file, we can look at it now.

Waterfall of part 2 of signal 5
We see 6 different channels, we can try to demodulate each of them. If we set a sample rate of 50kHz, then the channels are centered on 6kHz and evenly spaced of 2kHz. We can split them with GNURadio and analyze them independently.
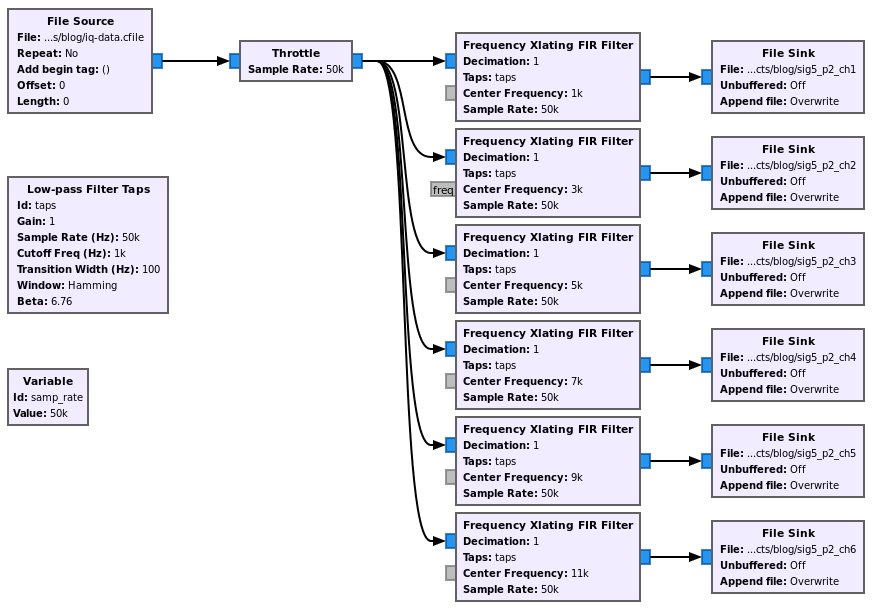
Channelize the part 2 of signal 5 with GNURadio
When trying the simple demodulations (amplitude, frequency, phase), we see that the phase and amplitude lead to interesting diagrams. Given that the phase still has some rotation, there is probably a little frequency offset which remains. However, we can still use the amplitude as is and perform the same demodulation than for signal 3 (OOK).

Amplitude of the part 2 of signal 5
Now that the channels are extracted, there are at least two possible ways to get the data from them:
- We can use the same method as for Signal 3 (find samples per symbol, then decode). This script will properly decode the channels when using sps=347.
- We can use URH and do an AM demodulation. Parameters are not auto-detected, but setting sps=347 (although URH is more permissive) and manually fixing the threshold for discriminating ones from zeros will correctly decode the channels.
If we go the manual way, here is the output :
b'\xaa\xaaz\x00\x15TheMouseTookStrollEOF\xc3\xe1kXgUT\xf4' -> TheMouseTookStrollEOF
b'\xaa\xaaz\x00\x1cFoxLookedGoodReallyBustedEOFR\x94\x19Z' -> FoxLookedGoodReallyBustedEOF
b'\xaa\xaaz\x00\x1bTheMouseJigsawRefillCoolEOF\xe6\xb0]\x80' -> TheMouseJigsawRefillCoolEOF
b'\xaa\xaaz\x00\x1eJigsawSidingRefillViscosityEOFL\xc1\xaf\xb8' -> JigsawSidingRefillViscosityEOF
b'\xaa\xaaz\x00\x1cComeLunchUndergroundHouseEOFG\xdc\x07\xe7\x90' -> ComeLunchUndergroundHouseEOF
b'\xaa\xaaz\x00\x1bTerriblyKindButNoWayRealEOF\x10\x9a\xb54' -> TerriblyKindButNoWayRealEOF
There is garbage at the end because there is some noise that is decoded. But in the frames, we see a structure. There is the preamble 0xAAAA, the sync word 0x7A, a null byte, the length of the payload and the data. This ends part 2.
Note: I think the modulation was BPSK due to how the phase looked like (after correction it was similar to a BPSK constellation). However, in this case it was also similar to amplitude OOK because the phase went from (0,0) to (1,0), therefore amplitude went from 0 to 1 exactly as in OOK.
Part 3
The 3rd part is the audio tones that we hear in the signal. It sounds like old telephones, when numbers were pressed. After searching a bit on the Internet, it turned out to be Dual Tone Multi frequency Signaling (DTMF), the wikipedia page provides some information about it.
As displayed on the spectrum, each character is encoded into two simultaneous tones. For example, 5 is encoded with a tone at 770Hz and at 1336Hz. There are four possible lower tones and four possible higher tones, totalling 16 possible characters. The characters that can be transmitted are “0123456789ABCD*#“, like phone keypads.
I did the demodulation and decoding by hand, which yielded the following sequence : 052084072035067072065078035070082079077035076069070084035083089078067035055065.
When I initially solved this challenge, I tried some combinations of this as flag, but it didn’t work. I looked for ways to encode ASCII into DTMF tones, but couldn’t find this exact type of encoding. Finally, looking closer we can notice this string is just numbers separated by 0.
I tried as hexadecimal and decimal encoding. The latter finally gave the part of the flag:
msg = "052084072035067072065078035070082079077035076069070084035083089078067035055065"
res = []
s = 1
while s < len(msg):
res.append(int(msg[s:s+2]))
s += 3
print(bytes(res))We find this part: ‘4TH#CHAN#FROM#LEFT#SYNC#7A’. It indicates that we actually need to take only one of the previous channels and not all six. Furthermore, EOF seems to indicate there is no more parts.
Conclusion
To verify if there were more parts, I looked for the original audio clip on Internet. It is the beginning of the documentary “James Stewart’s Ballistic Missile Early Warning System”. Comparing the audio, what I thought was maybe a 4th part was in fact included in the original audio.
That means we have all the parts needed. In the end, the flag is TMCTF{SOS-STEGHIDE-TOOL-F1N1CKY5HUT_4TH#CHAN#FROM#LEFT#SYNC#7A_JigsawSidingRefillViscosityEOF}.
Level 4
Signal 6
File: capture_custom_RF.cfile
The only indication we have is that “The challenge looks like TMCTF{

Waterfall of Signal 6
On the waterfall, we see it is a kind of frequency modulation. There are three distinct frequencies, however on the waterfall we see that the lower one seems always on.
At first, I believed the data was encoded only on the two higher channels, and that the lower one was a kind of CW. I had tried several encodings for the higher two channels, but those didn’t work (tried standard 2-FSK, some frame structure, Morse code, …)
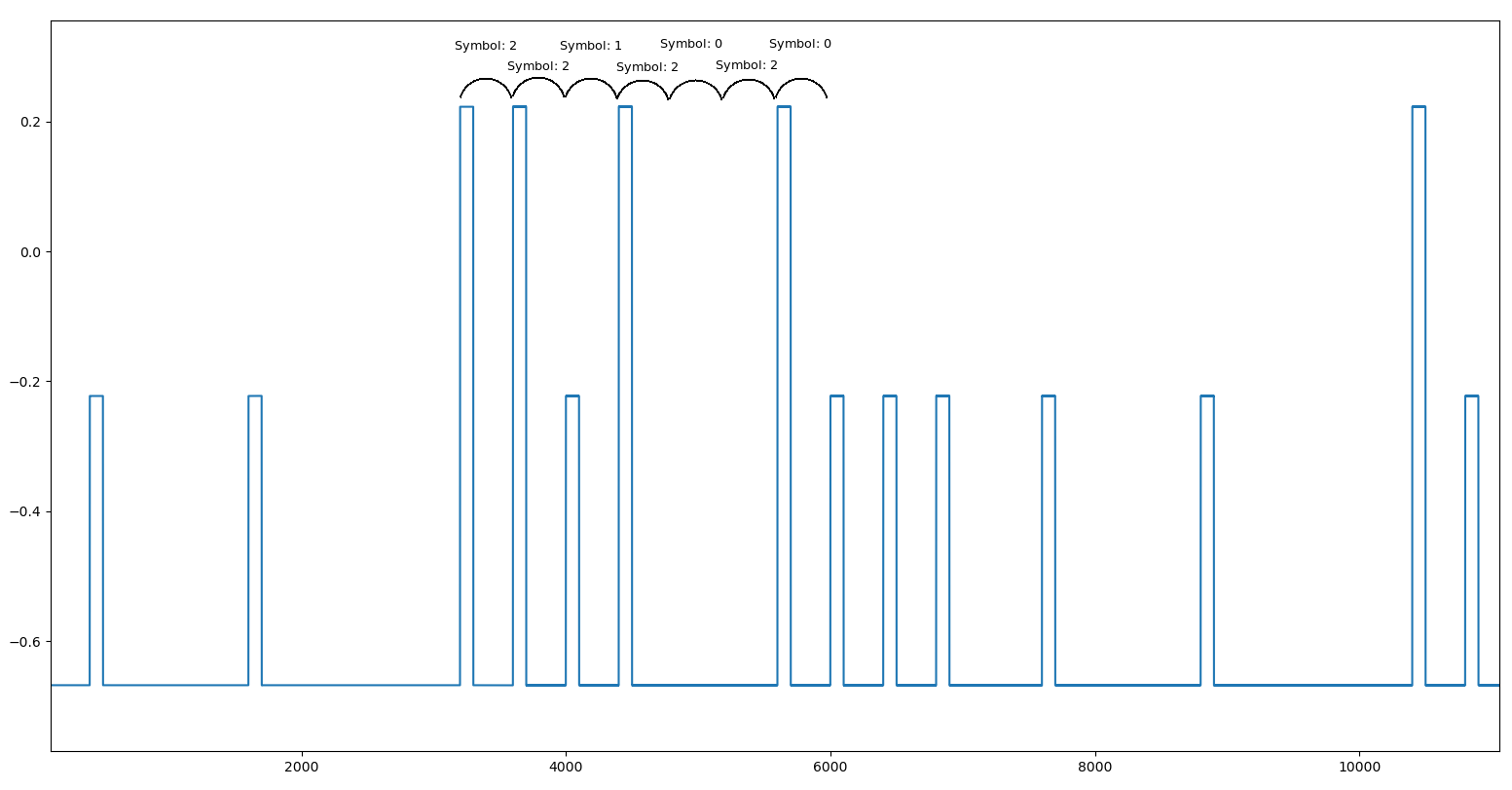
Instantaneous frequency of Signal 6 - start of transmission
If we (again) assume that the sample per symbol is constant, then we can clearly identify that a symbol is encoded by a certain frequency value, followed by a blank (cf image).
After unsuccessful tries, I attacked this challenge as a cryptanalysis challenge. If we assume that a character of the flag always has the same encoding, then it can be viewed as a (sort of) monoalphabetic substitution cipher. Having identified the sample per symbol (here, sps=400), we can demodulate the signal.
The first thing to do is to identify the number of symbols used to encode a character. By trying all of them, we see that multiples of 6 align really well. For example, here are the first blocks of 6 symbols:
010010
002212
002111
010010
002121
011120
010012
001210
011102
001220
010201
010112
010000
011100
001221
011000
Then, we notice that the first and fourth block are the same. Given that we expect the flag to start with “TMCTF”, this may mean that “010010” is the encoding of “T”. Using this hypothesis, we can fill the letters T,M,C and F. Also, after poking with block frequencies, we can notice that the block “010112” comes every eight or nine blocks. Given we are looking for a flag, this may be a separator character, like ‘#’, ‘,’, ‘_‘. Unfortunately, even after those substitutions the flag didn’t really make sense: ‘TMCTF……_……._…….M_………_………_…….._…….._…….._………_…….._……._……..’
After a while, I got the idea of ternary encoding and tried that. This hypothesis was coherent with the number of symbols used to encode a character. In the end, the flag is indeed modulated with a 3-FSK and the encoding is ternary. Bytes are sent MSB-first.
The script that does demodulation and decoding is here:
import numpy as np
from matplotlib import pyplot as plt
sig = np.fromfile("capture_custom_RF.cfile", dtype=np.complex64)
freq = np.diff(np.unwrap(np.angle(sig)))
# Demodulation
sps = 400
start = 50
res = ""
while start < len(freq):
if freq[start] > 0:
res += "2"
elif freq[start] > -0.4:
res += "1"
else:
res += "0"
start += sps
# Separate blocks
start = 0
blocks = []
while start+6 < len(res):
blocks.append(res[start:start+6])
print(res[start:start+6])
start += 6
# Decode
res = []
for b in blocks:
cur_mul = 1
cur_chr = 0
for a in b[::-1]:
if a == "1":
cur_chr += cur_mul
elif a == "2":
cur_chr += cur_mul * 2
cur_mul *= 3
res.append(cur_chr)
print(bytes(res))We finally get the flag: TMCTF{V0w3d_Qu4l!fy_k!l0gRaM_nu77!n3ss_3ff3ctiv3_cOntemp7_
h4ndcuff_pl4typuS_r3futable_dEputize_Pr3tz3l_r3th!nk}.
Looking at the final flag, it would have been very hard to complete it the cryptanalysis way, as there are not many characters to work with and words use an alternative spelling.
Signal 7
File: capture.pncapng
Description:
something.in.the.air
Our investigation led us to a remote server located somewhere up in northern
cold countries.
We got a physical dump, but something looks weird as if the main transmission
happened "beyond the wire".
At that time, VoIP IMs were not there and other short message services were
used.
Maybe like a sort of re-invited primitive covert channel?
Hint: Other default parameters might been tampered, but the capture was at 1Msps.
The flag format is TMCTF{<the actual flag>}
Part 1
We have a pcap file, and looking at it with Wireshark we see it was a USB communication.
This challenge was partially solved during the HW.IO CTS by someone (during HW.IO, no one was able to completely solved it, this is one of the two challenges that was solved only once at GRCon). The partial write-up is located here.
The first part of the challenge is explained in the write-up above, however the method is incorrect (yields an invalid file).
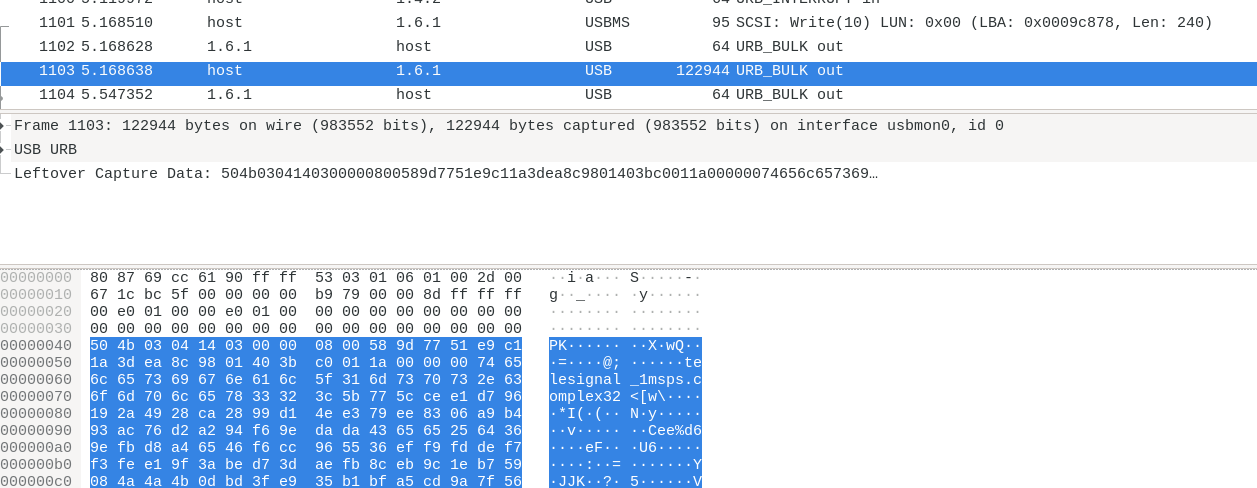
Signal 7 capture - Zip header
In this packet, we see an interesting filename. Furthermore, the “PK” header indicates a Zip file. We see that there are several USB writes, whose addresses are are consecutive: this means that if we extract the USB data from the wireshark capture, we will have an ordered file. All the interesting packets have a big size (>100000 bytes), which enables easy filtering.
We can recover the file:
tshark -r capture.pcapng -2 -R "frame.len > 100000" -T fields -e usb.capdata | xxd -r -p > data.zip
unzip data.zip
We get the file telesignal_1msps.complex32. The file given in the repo of the partial write-up is incorrect. It mentions using binwalk on the output of the extracted data, although I don’t exactly know where it failed. Anyway, we can proceed with ours.
Part 2
Now that we have our file, the partial write-up also included the hints for this challenge. Those were:
- The transmission might contain polluted packets.
- Other default parameters might been tampered, but the capture was at 1Msps.
- ARFCN 34
In particular, the “ARFCN 34” is indicative of GSM (2G) data. In the description of the task, “IMS” is indicative of telecommunication protocols (IP Media Subsystem, is used for SMS, voice service in 4G and beyond). “short messaging service” is also indicative of GSM, because this is the meaning of “SMS”. To work with GSM signals, the GNURadio out of tree module gr-gsm is useful.
Signal 7 IQ file - Waterfall
On the waterfall, we see there seems to be two distinct signals: one centered at ~200kHz and the other centered at ~400kHz. GSM channels are 200kHz large, so the 2nd transmission may be our GSM channel. First, we recenter this transmission by mixing it with a 404kHz cosine and using a +/- 150kHz low pass filter.
There are several blogposts already which explain how to use gr-gsm. The executable of interest here is grgsm_decode which is able to decode a signal.
At this point, I broke two of my GNURadio installs due to version mismatch between distro packages/python packages and manual installations.
So I ended up with a minimal Ubuntu 21.04 VM, where it is possible to easily install gr-gsm with apt-get install gr-gsm.
The tool grgsm_decode automatically sends decoded packets to localhost:4729 in UDP.
First, start Wireshark : wireshark -k -Y gsmtap -i lo
Then, we can decode the Broadcast channel in GSM : grgsm_decode -a 34 -c gsm.iq -t 0 -m BCCH
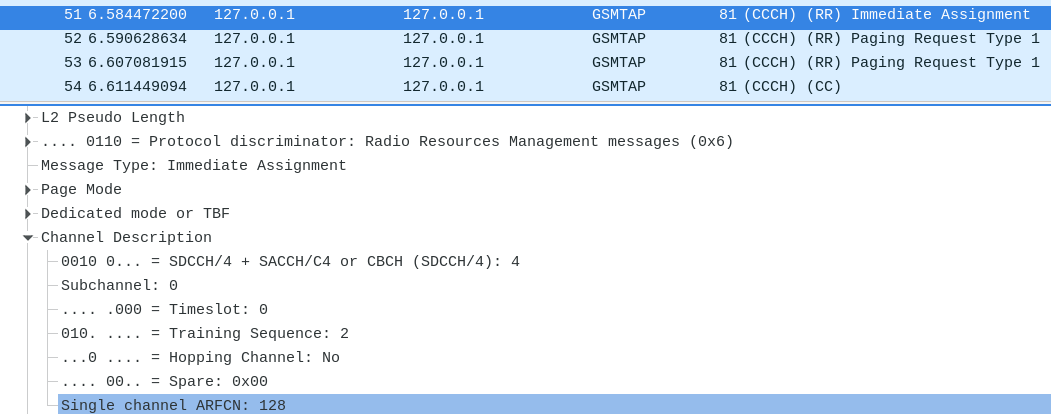
Signal 7 GSM capture - Immediate Assignment
There is one packet of type “Immediate Assignment”, which indicates an equipment is connecting to the network. In this packet, we need the channel description :
- Timeslot (it is 0)
- SDCCH4
Now, we can decode the control channel of the connection : grgsm_decode -a 34 -c gsm.iq -t 0 -m BCCH_SDCCH4
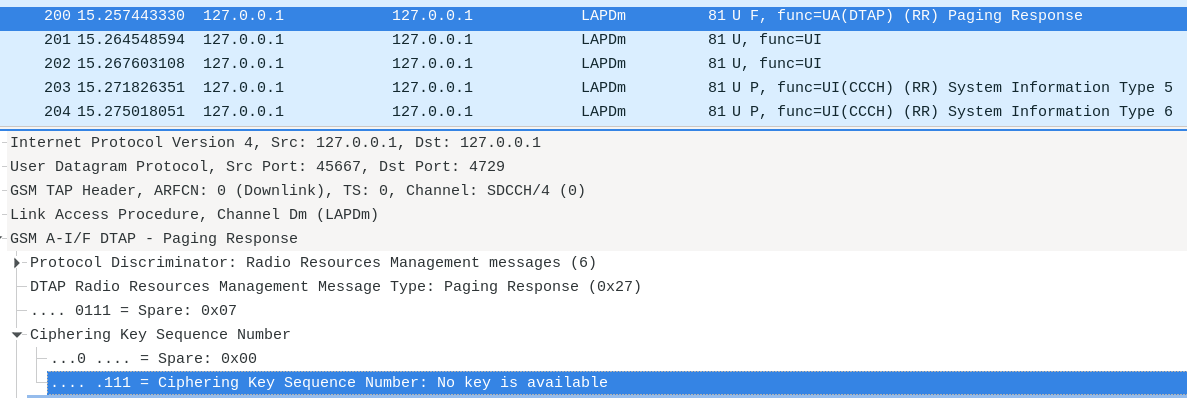
We see new packets in Wireshark. In particular, the “Paging Response” indicates that there is no encryption key available, meaning that the data sent won’t be encrypted.
Signal 7 GSM capture - Paging Response
Signal 7 GSM capture - SMS data
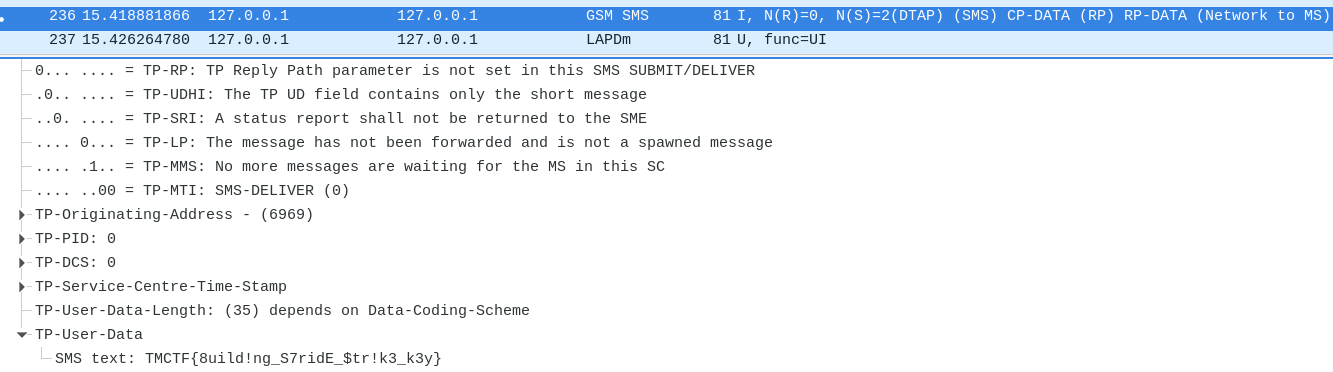
Finally, we can see a decoded SMS packet which was not encrypted. We can read the content of the SMS : TMCTF{8uild!ng_S7ridE_$tr!k3_k3y}.
Level 5
Signal 8
File: signal8.iqdata
The description of the task is short: Sync 0xc0ffffee.

Signal 8 Waterfall
In the file, there are four different bursts.
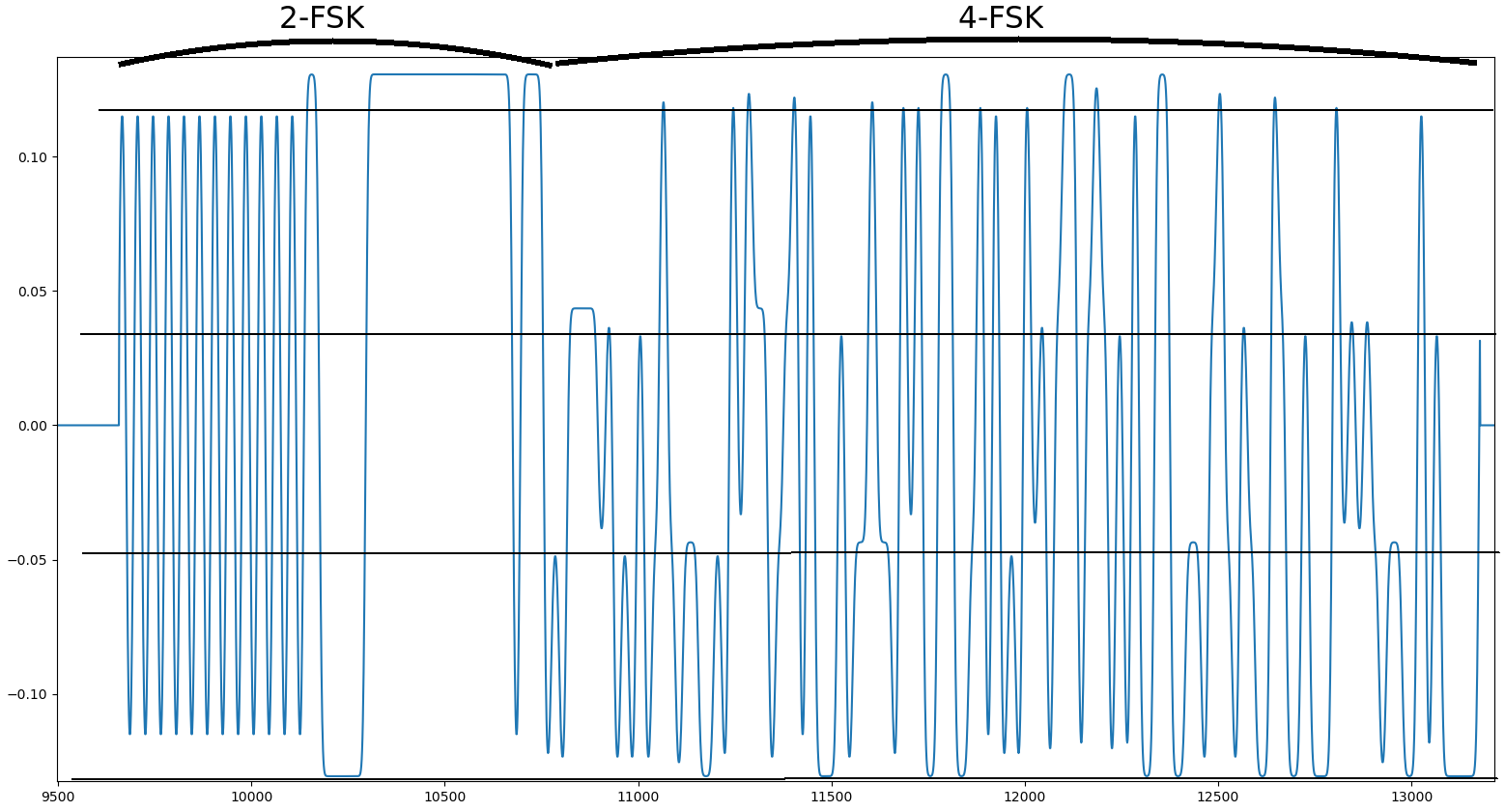
Signal 8 - Instantaneous frequency of a burst
On the graph of instantaneous frequency, we see that on the first part, there are 2 frequency levels and on the second part, there are 4. We can match the sync word “0xc0ffffee” to the header of the file, which validates the 2-FSK hypothesis. For the 4-FSK, we can try to demodulate and decode the data.
The first packet begins at sample 9666 and ends at sample 13165, with a sample per symbol of 20. The demodulation is similar to what was done for 3-FSK of Signal 6, with 4 levels instead of 3.
import numpy as np
import itertools
sig = np.fromfile("signal8.iqdata", dtype=np.complex64)
freq = np.diff(np.unwrap(phase))
#sync: 0xc0ffffee
# Re-sample the signal
start = 9666
sps = 20
end = start + 176*sps
samples = []
while start < end:
samples.append(freq[start])
start += sps
# Demodulate the data
syms = []
for s in samples:
if s > 0.1:
syms.append(3)
elif s > 0:
syms.append(2)
elif s > -0.1:
syms.append(1)
else:
syms.append(0)
data = syms[7*8:] # Remove header
# Try all possible encoding permutations
syms = ["00", "01", "10", "11"]
for perm in itertools.permutations(syms):
res = ""
for s in data:
res += perm[s]
print(bytes.fromhex(hex(int(res, 2))[2:]))Among the tested encodings, one yields the correct flag: \x1a\xa2FLAG:Kud0s_Strong_Player!\x05\xd9U.
Overall, the encoding was more straightforward than for signal 6, the difficulty came from the fact that the modulation changed between header and data.
Signal 9
File: 1983.tgz (1.5G)
This was the most difficult challenge of the CTS and the very last one I solved. This was also the most fun, as it involves many elements: radio of course (analog and digital), some googling skill/specification reading and a bit of cryptography. Many thanks to its creator(s) !!!
The description is rather verbose:
Sig Int: 1983
Its 1983 and you are a signals intelligence agent and your agency has
provided some recently recorded electronic communications between hostile
foreign agents for you to analyze. Progressively decoding the signals
will result in discovery of the flag.
There are two types of recorded communications. First, telephone audio
recordings (*.wav) containing voice and data communications. The foreign
agents are known to use PX-1000 communication devices.
The second type of signal is over the air radio data recorded in CF32 I/Q
format (*.iq). CF32 is a raw format (no header), containing pairs of
32-bit floats representing I and Q for each radio sample. The foreign
agents are known to use analog radio communications to deliver cryptographic
key material.
Signal file names indicate the date, time and source of the recording.
Good luck!
As indicated, the archive contains three files :
- 1983⁄1_1983-07-0212-35+74957285000.wav
- 1983⁄2_1983-07-03_03-40_108925000Hz.iq
- 1983⁄3_1983-07-0417-25+74957285000.wav
If we read the scenario, the first file was recorded first, then the second, then the third.
For solving this, I quickly completed part 1, then came back and forth between part 2 and 3 and solved them at about the same time.
Part 1
Let’s take on the first file. This is a single audio recording between a presumed foreign agent and an operator. The operator asks questions about a “package delivery”. We hear DTMF tones, just like in Signal 5: it seems the agent is answering the operator’s questions using the phone keypad.

Signal 9 - Part 1 Waterfall
DTMF tones were decoded by hand. The transcript of the conversation is:
- Welcome to the package delivery service. Please key your ID.
- 15728 (DTMF)
- Key your desired delivery time
- 0345 (DTMF)
- Key your desired delivery frequency
- 109 (DTMF)
- Thank you, please enjoy your package. Good Bye.
Looking at the scenario and the conversation, we assume the “package” is the cryptographic material which is exchanged using said “analog radio communications”.
Part 2
The part 2 consists in a big IQ file.
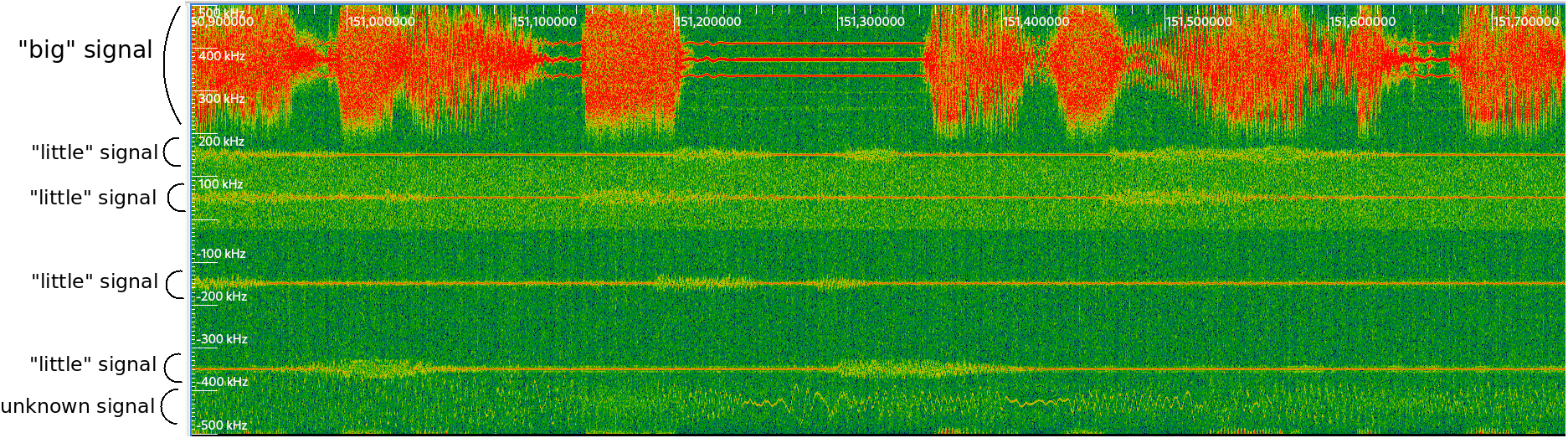
Signal 9 - Part 2 Waterfall
Just looking at it doesn’t help much: there are lots of signals, which appear and disappear. There is one big one which is always here. We have the information about the frequency of the signal (~109MHz), but not about the sample rate or its content.
Given the size of the file and year, I thought about a TEMPEST challenge first. But after trying TempestSDR, nothing came up.
So I just listened to the signal, hear if my ear could detect some patterns. The sample rate was set to 384kHz because it is the best my sound card offers.
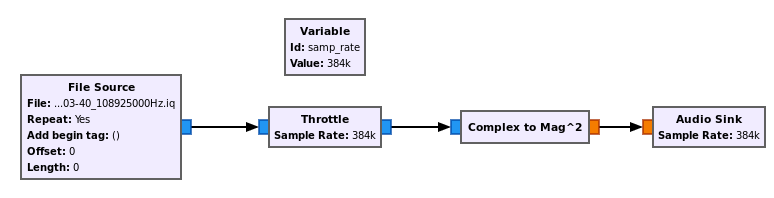
Signal 9 - AM Demod
It turned out to be the good first step: we hear an AM radio station. After some peeking, it is carried by the “big” signal. Given the little signals have a much narrower bandwidth and intensity, I supposed they were FM signals.
If we assume a sample rate of 384kHz, the little signals are (in order of appearance) :
- Channel 1: -19kHz, starts at 0.8s
- Channel 2: -95kHz, starts at 45.6s
- Channel 3: 20kHz, starts at 97.7s
- Channel 4: 172kHz, starts at 182.3s
- Channel 5: 133kHz, starts at 371.1s
- Channel 6: 59kHz, starts at 390.6s
- Channel 7: -57kHz, starts at 390.6s
We can extract all of them with GNURadio.
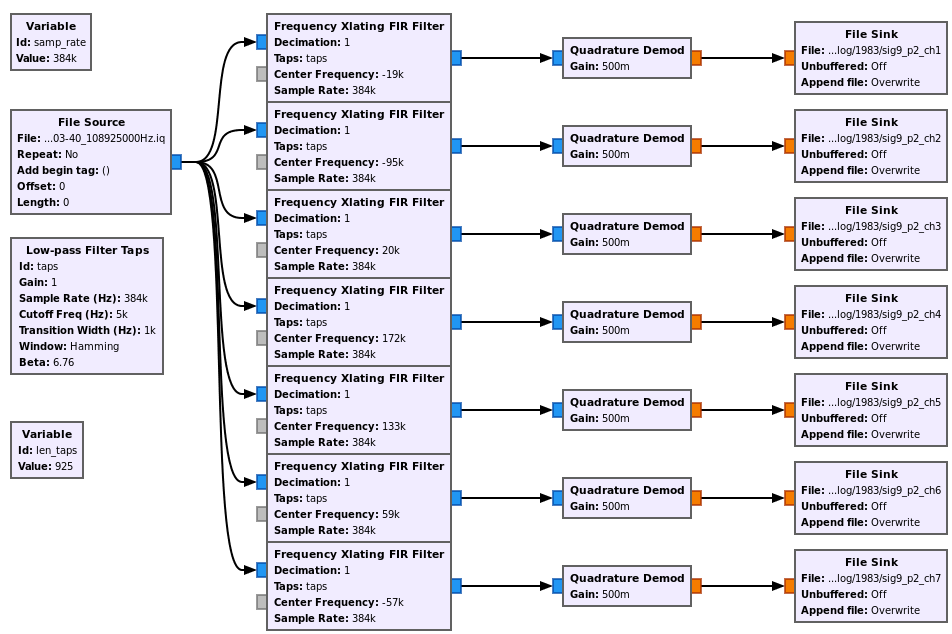
Signal 9 - Channel extraction and FM Demod

Signal 9 - Channel 1 on Audacity
On Audacity, we can see the transmission on the first channel (in order of appearance), which disappears at about 1:38. If we listen to it, we recognize a human voice, spelling numbers.
Note: When solving the challenge, I made a mistake in my import in Audacity. I treated samples as signed 32-bits PCM (instead of floats). However, voices were still recognizable.
All the channels contain an operator spelling numbers (there might be a lot of “package delivery” at the same time at this frequency), we have to find the right one.
Here is what I could understand for each channel:
- ch1:
Given that channels 3, 4 and 5 were very noisy, maybe the demodulation was off. Also, I didn’t perform some audio processing after demodulation, which didn’t help the understanding. But we see that on channel 6, which was rather clear, there is the id of the agent (from part 1) repeated, before a string of eight numbers. Because of the id, this may be the channel of interest.
Determining the exact channel also depends on the part 3 (i.e. which format is the cryptographic material supposed to have). At the end of this section I wasn’t exactly sure the channel 6 had the correct information, but it was the most reasonable guess at the moment and I deemed more interesting to finish part 3 before investigating further channels.
Part 3
For this part, we are given a wav file.

Signal 9 - Audacity view of part 3
If we zoom enough, we see that it looks like a frequency modulation. To verify that, we can plot the instantaneous frequency of the signal. As I prefer to work with complex signals rather than real ones, I first make the conversion with GNURadio. We can do that with the “Hilbert transform” block in GNURadio.
Signal 9 - Part 3 - Conversion to complex signal in GNURadio
Signal 9 - Part 3 - Instantaneous Frequency

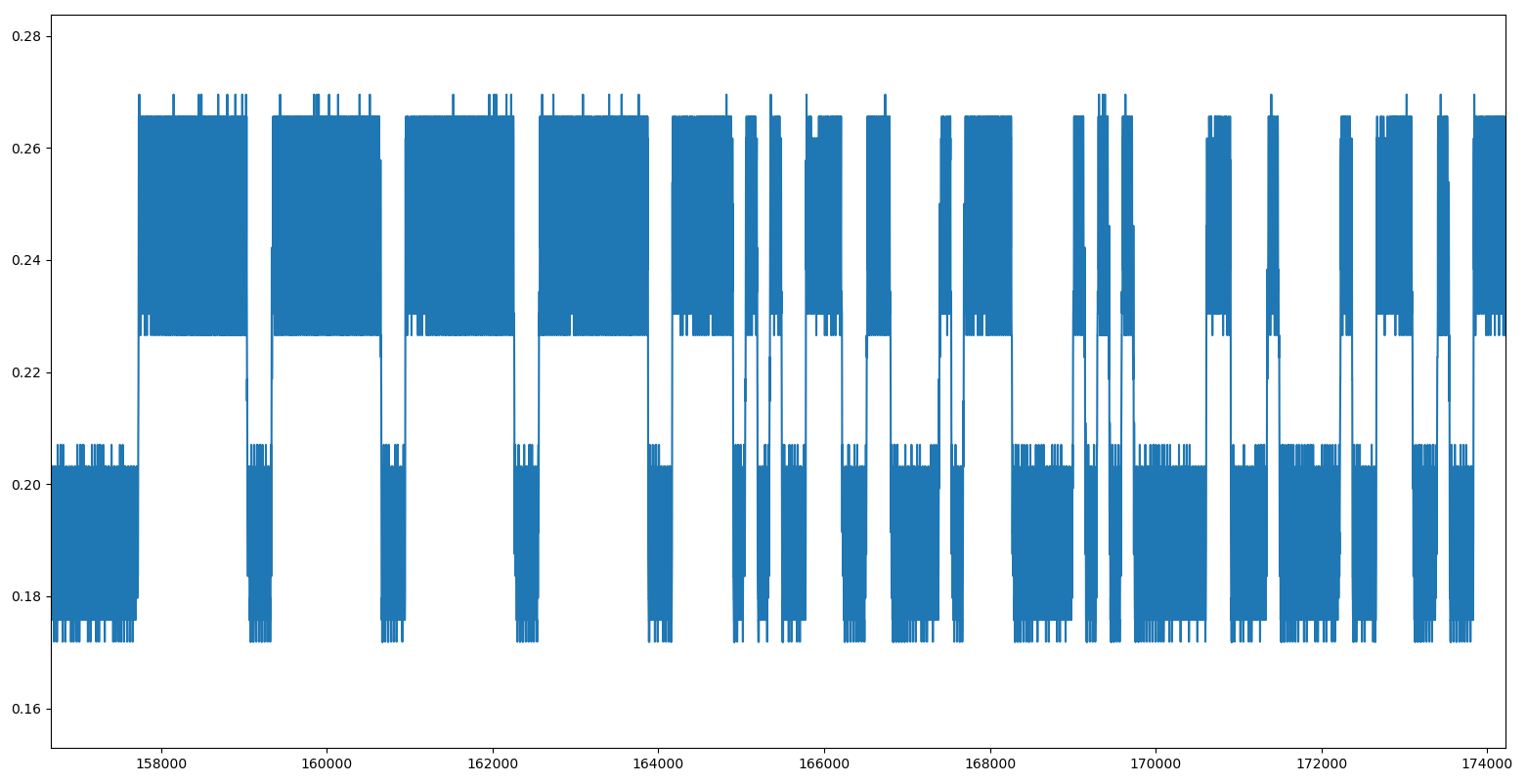
On the frequency plot, we can confirm the 2-FSK hypothesis. Back to the description of the challenge, there is one element that we have not used yet: the communications using PX-1000 device.
When looking on Internet, the Crypto Museum has many information about it. The PX-1000 is a communication device to transmit text over audio frequencies. It has a function to encrypt and decrypt communications using DES. In 1984, another model of PX-1000 was available, where the NSA had replaced the DES algorithm with a custom one.
At first, I thought that the PX-1000 was used to encrypt the communications, based on the key material previously exchanged. In the documentation (1,2). I looked for the following elements:
- Modulation used
- Data encoding
- Key derivation
- Exact encryption algorithm/mode used
The first two points were easy to solve, but for the other two only vague information is available in the manual. The modulation is indeed 2-FSK, using symbols MARK (1) and SPACE (0). The documentation explains that the cryptographic key to enter is composed of 16 characters, but not how it is derived in the DES key. Similarly, which data is encrypted exactly and how is not detailed.
The information already mismatch the guess made in part 2: the manual says we need to enter a 16-character key, but the “package” found is only 8-chars long.
Still, this is not yet a dead end because we can at least demodulate the signal and see if there are some indications inside. Data encoding is the following:
+-------------+-------------+--------------+-------------+
| 1 start bit | 7 data bits | 1 parity bit | 2 stop bits |
| | (LSB first) | | |
+-------------+-------------+--------------+-------------+
In fact, there is a mismatch between the Operating Instructions and the Service Manual of the PX-1000. For the audio transmission encoding, one states there are 7 data bits while the other states there are 8. Because we don’t know which version is correct, we may have to try both. We can also confirm that the signal comes from a PX-1000 by looking at the header and verifying it manually: it matches the documentation.
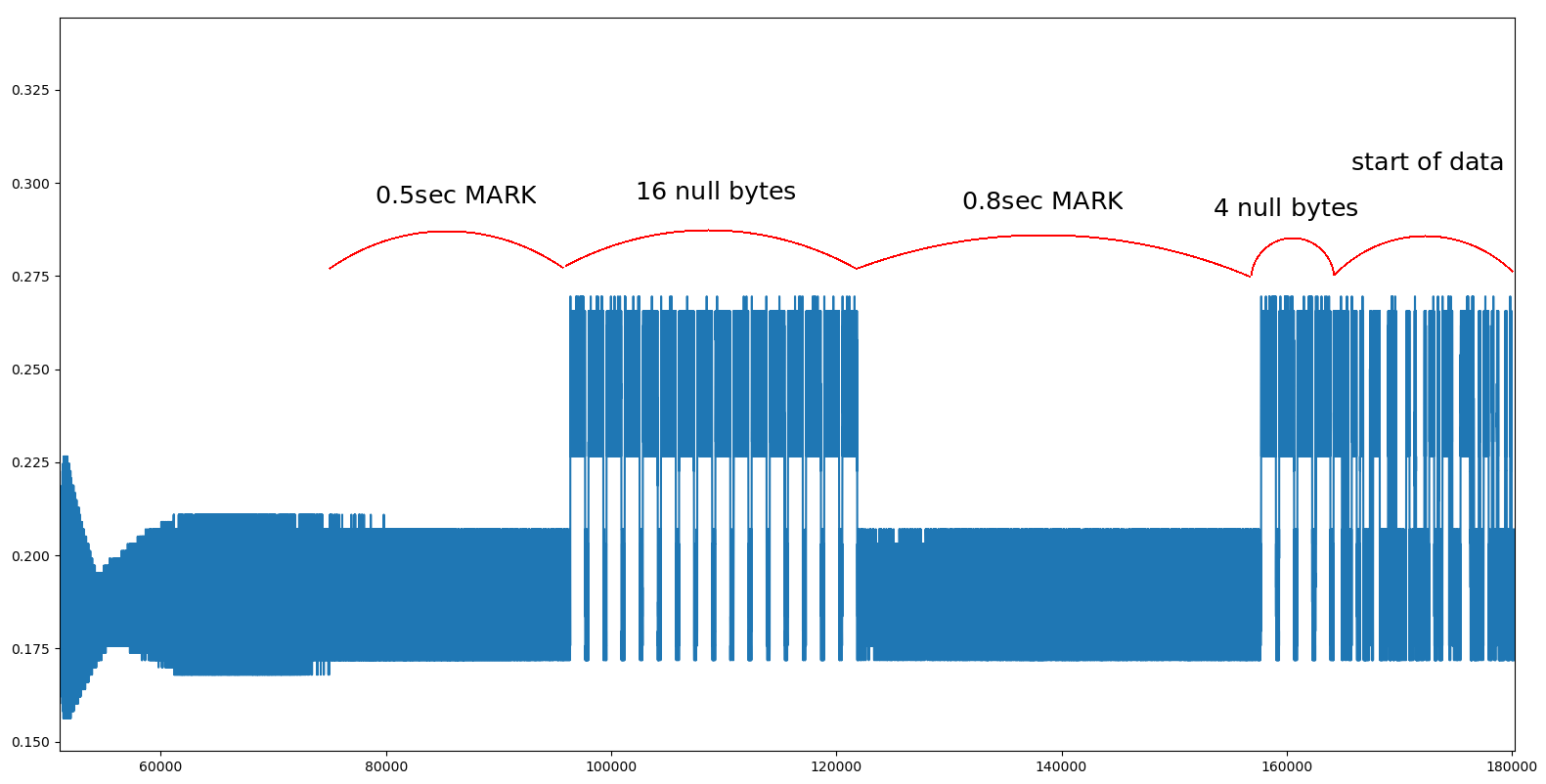
Signal 9 - Part 3 - PX-1000 Transmission Header
We can demodulate the signal with the same type of script than for previous ones. First, count the number of samples needed to encode a low or high state: this will give the number of samples per symbol. Then, re-sample with this value and extract the bits.
import numpy as np
#from matplotlib import pyplot as plt
sig = np.fromfile("sig9_p3.iq", dtype=np.complex64)
f = np.diff(np.unwrap(np.angle(sig))) # Frequency demodulation
# Get the number of samples used to encode each successive high state or low state
start = 157730 # start of frame
end = start+159050 # end of frame
thresh = 0.215 # Threshold to discriminate MARK from SPACE
counts = []
prev = 1
c = 1
while start < end:
if f[start] > thresh:
if prev == 1:
c += 1
else:
counts.append(c)
prev = 1
c = 1
else:
if prev == 0:
c += 1
else:
counts.append(c)
prev = 0
c = 1
start += 1
# plt.hist(counts, bins=50)
# plt.show()
# We have the expected evenly spaced bins, the sample per symbol is about 145.
# Get the bitstream from the demodulated signal
sps = 135 # Easier to take a slightly lower value to save a few lines for finding number of symbols encoded in a low or high state
start = 157730
cur = "0"
res = ""
for c in counts:
res += cur * (c // sps)
if c >= sps:
cur = "0" if cur == "1" else "1"
# Repack the bitstream into 11-bit blocks
blocks = [] s = 0
while s + 11 < len(res):
b = res[s:s+11]
# print(b)
blocks.append(b)
s += 11When displaying the first blocks, we have:
00000000011
00000000011
00000000011
00000000011
00000101011
00011001111
01000011111
01010111111
The start of the decoded frame was chosen as the end of the header. We recognize the four null-bytes which end the header. This also validates the 11-bit structure of the frame from the PX-1000 Service Manual instead of the 12-bit structure described in the PX-1000 Operating Instructions. We can verify the validity of the blocks using the start, stop and parity bits and print the encoded message.
msg = []
for b in blocks:
parity = sum(list(map(int,b[1:8]))) & 1
if b[0] != "0":
print("Error start bit")
if b[9:] != "11":
print("Error stop bit")
if parity != int(b[8]):
print("Parity error")
msg.append(int(b[1:8][::-1], 2))
print(bytes(msg))The message contained in the PX-1000 transmission is b'\x00\x00\x00\x00PLaunch code: 6AFD7E01F8EB51B2FBF49CBF17F2F3E5A44099B6410DF9BC\r\x04\x04\x04 ...' (padding with 0x04).
Given the output, we conclude that the demodulation and decoding was successful.
Part 4
When attacking the PX-1000 transmission I strongly believed that the encryption feature was not used. However, given that we are able to make sense of the message, this hypothesis proved to be wrong.
In part 2, we ended up with a series of 8 digits that was believed to be some cryptographic material. The PX-1000 transmission gave us an hexadecimal string which really looks like a ciphertext. When decoded, the ciphertext is 24-bytes long.
Presumably, we need to find the encryption algorithm used to reverse it. Given there are no additional hints, I tried common encodings of digits (raw bytes, ascii) and common encryption methods for 1983: xor, DES in ECB mode and DES in CBC mode with several possible IVs.
In the end, we had to use DES in ECB mode and the key encoded in ascii:
from Crypto.Cipher import DES
key = b"32179365"
ciphertext = bytes.fromhex("6AFD7E01F8EB51B2FBF49CBF17F2F3E5A44099B6410DF9BC")
cipher = DES.new(key, DES.MODE_ECB)
print(cipher.decrypt(ciphertext))This gives us the flag: TMCTF[7nkgRy6X#phy5e*?]. To enter it on CTFd, we need to replace ‘[]’ with ‘{}’ and that’s it !
Final thoughts
This was a very fun CTF. For the vast majority, the signals were simple demodulations and decoding, but some went way beyond that. I particularly enjoyed the last challenge, which was the most fun to solve (at least for me). I think the scenario and different steps were rather spot on: for each part, we had to use the most basic (i.e. did not need convoluted guesses) possible solution from the signals observed and solve it this way. Because of the links between the tasks, we had some assurance that we were on the right track and this was enjoyable (particularly when listening to all signals in part 2, which was a bit daunting).
Again, thanks to the organizers and to the creators of the challenges for this experience. Thanks also to the community for the variety of tools available to do signal processing and investigation: GNURadio of course, URH, Inspectrum, SigDigger, gqrx, …


